


At Hot Chips 2024, OpenAI will be giving an hour-long keynote on building a scalable AI infrastructure. This makes a lot of sense, as OpenAI as an organization consumes a lot of computing power and will likely consume even more in the coming years.
Please note that we are running these live at Hot Chips 2024 this week, so please excuse any typos.
OpenAI keynote on building a scalable AI infrastructure
I think most of our readers are familiar with ChatGPT and OpenAI and how LLMs work. We’ll just show the next few slides as I think our readers have that understanding.



In terms of scale, the idea is that GPT-1 was cool in 2018. GPT-2 was more coherent. GPT-3 had contextual learning. GPT-4 is actually useful. Future models with new behaviors are expected to be even more useful.
An important observation is that scaling creates better and more useful AI.

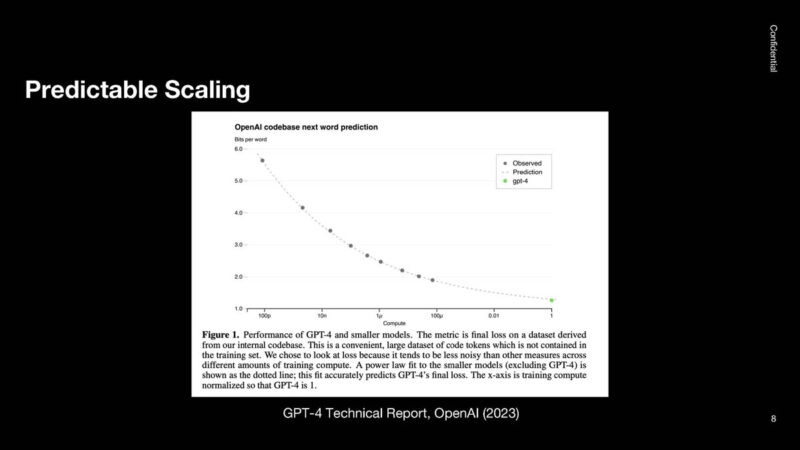
The question was how OpenAI would know if training a larger model would produce a better model. OpenAI found that every time the compute power was doubled, it produced better results. The graph below shows a four orders of magnitude increase in compute power, and the scaling still works.
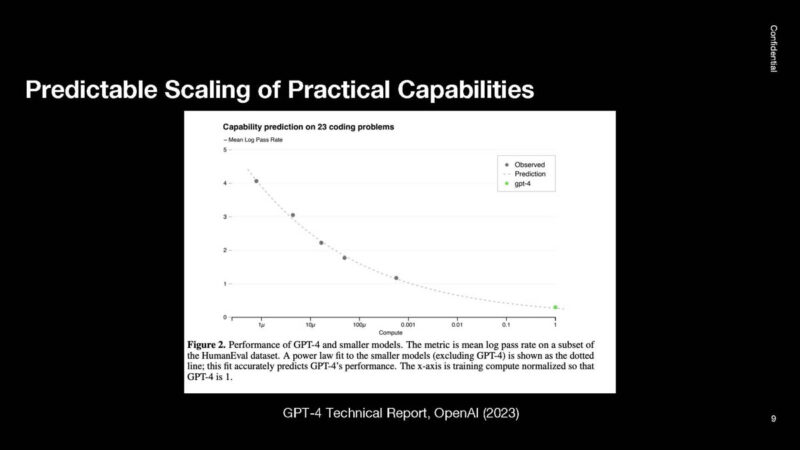
OpenAI looked at tasks like coding and found that a similar pattern was observed. This was done on a logarithmic mean scale so that pass/fail was not too biased towards solving simple coding problems.
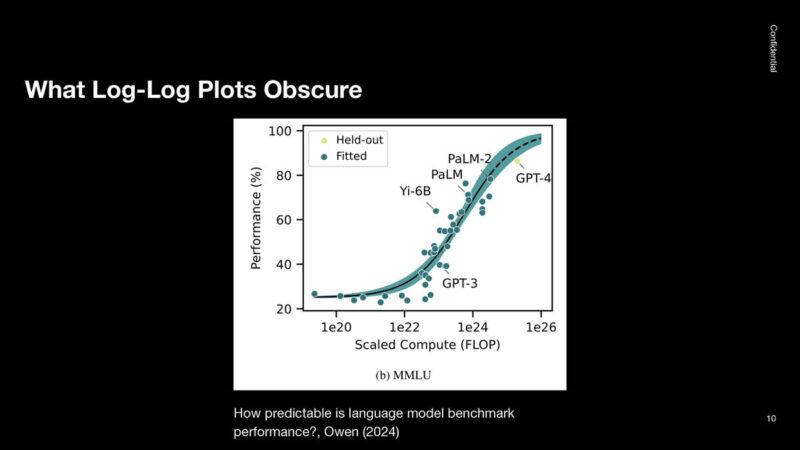
This is the MMLU benchmark. This is an attempt to be the ultimate machine learning benchmark, but due to logarithmic progression, GPT-4 already achieved ~90% in the test.
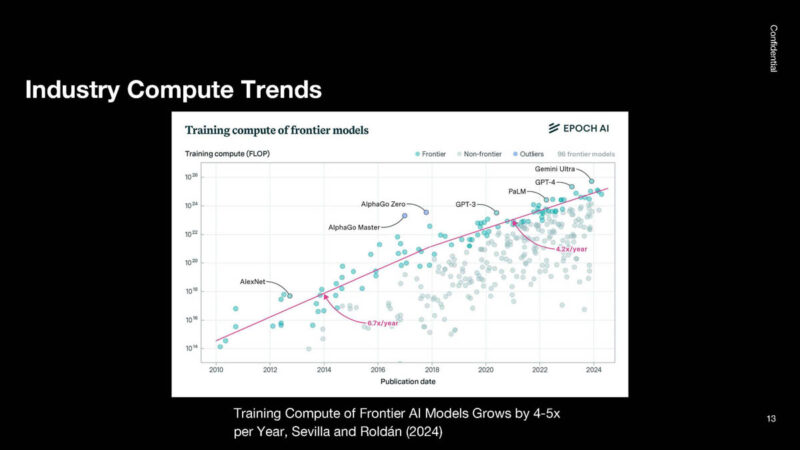
This is a representation of the industry calculations used to train various frontier models. The number has increased fourfold annually since 2018.
GPT-1 was a box for a few weeks. It was scaled to take advantage of large GPU clusters.

In 2018, computing power went from growing 6-7x per year to growing 4x per year. The idea is that in 2018, many of the easily achievable goals were achieved. In the future, things like cost and power consumption will be more of a challenge.
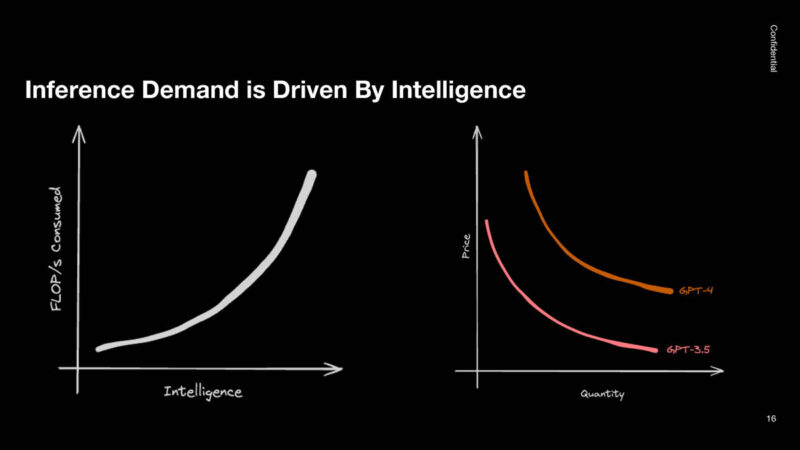
On the inference side, demand is driven by intelligence. The majority of compute power for inference is used for top-end models. The smaller models tend to require much less compute power. The demand for inference GPUs is growing significantly.
Here are the three best arguments for AI computing.

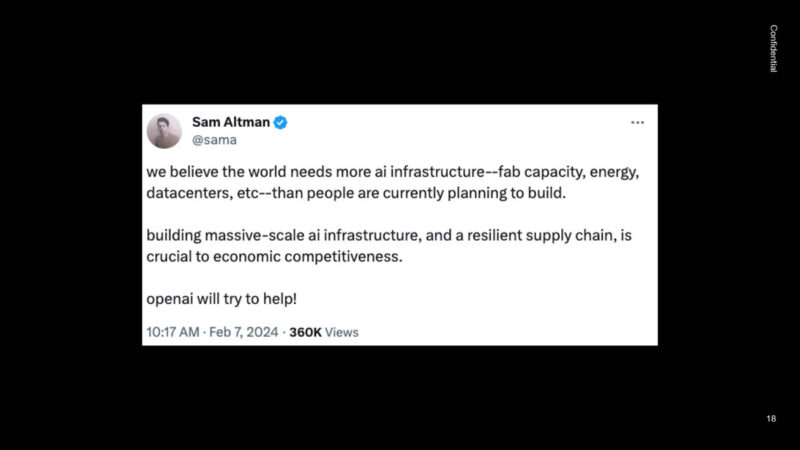
The idea behind it is that the world needs more AI infrastructure than it plans.
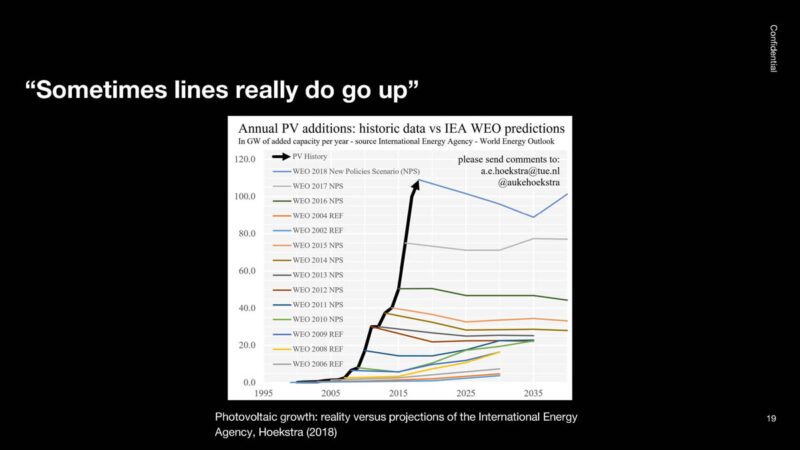
Here is the actual solar demand in black, here are expert forecasts of demand. Although the line continued to go up, the experts did not agree.
For about 50 years, Moore’s Law continued to rise for longer than many would have thought possible.
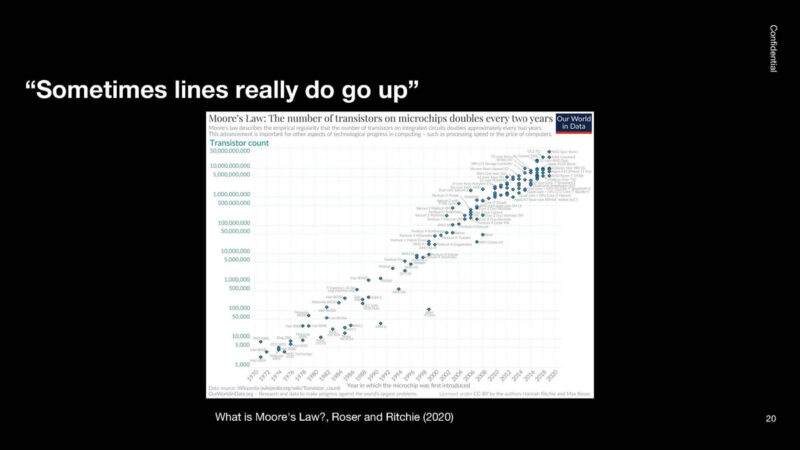
OpenAI therefore believes that massive investment is needed in the field of AI, as increases in computing power have already brought benefits of over eight orders of magnitude.
OpenAI says we need to design for mass deployment. One example is RAS. Clusters get so large that hard and soft failures occur. Silent data corruption occurs, which is sometimes not reproducible even if you can isolate the GPU. Cluster failures have a large explosion radius.

OpenAI says that repair costs need to be reduced. The blast radius needs to be reduced so that when one component fails, fewer other components fail.

One idea is to use graceful degradation. This is very similar to what we do at STH in our hosting clusters, so it doesn’t require engineer time. Validation is also important at scale.

Power supply will be a major challenge as the amount of electricity available worldwide is limited. GPUs will all be powering up and powering down at the same time, causing stress issues for data centers.

Like our key findings, OpenAI also has findings. I leave these for you to read:

Interestingly, performance is only one of the four points, although all focus on performance.
Closing words
The challenges at scaling and at the cluster level are enormous. If we look at the Top500, today’s large AI clusters are roughly similar to the top 3-4 systems on that list combined. It was cool to hear a large customer talk about how they see the need for AI hardware.



